
Now that we know how to setup a rails application using Dokku on a DigitalOcean droplet, it might be a good time to think about automating our database backups. If you haven’t read the first part, you should do it before reading any further.
Sure, you can enable weekly backups of your whole droplet on DigitalOcean (the cost is minimal), but for a database it is wiser to backup at least once a day. Let’s configure the whole thing. We are freelancers (or small development teams) and we are used to get our hands dirty and do stuff by ourselves. It’s not a question of not having enough money to pay someone else, it’s because we are smart and resourceful! See, it already feels better when we see it in this light!
We will use SpiderOak to store our backups. Their zero-knowledge architecture will make sure our data remains private.
UPDATE: Whilst SpiderOak is not free, they offer a 60-days free trial for 2GB storage (no credit card required). After that, the cost is $7 per month for 30 GB storage. Thanks to NoName in the comments for asking me to clarify this point.
Create an account on SpiderOak
We will first install the client on our local workstation and create our account.
On the SpiderOak page, click on downloads
Then, choose the correct client for your distribution:
Run the installer. You should be presented with the following screen:
Next step is to register your local computer with SpiderOak.
Finally, you will be presented a screen to select what you want to sync from your local computer to the cloud. You can leave the default options for now:
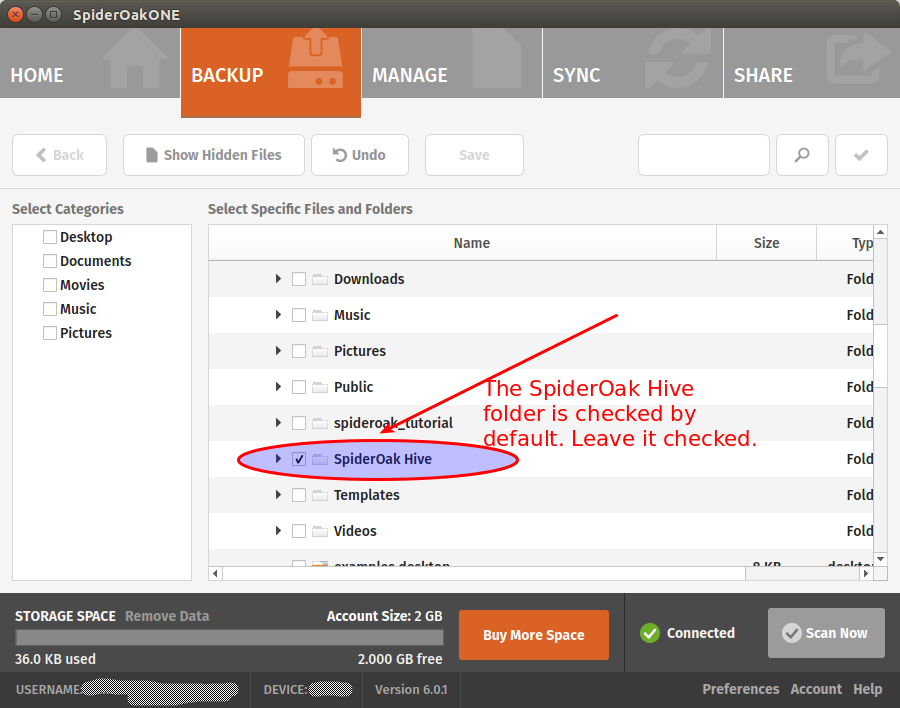
We won’t use the SpiderOak “Hive” folder
SpiderOak creates the SpiderOak Hive folder in the installation process. All files added to the Hive folder of a device are automatically synced to the Hive folder in every other devices. It is a convenient way to have things running quickly without configuring shared folders manually. One problem of using the Hive for our backups is that it will sync everything. You put something personal in your Hive on your local computer and oops, it will be sent to your droplet! That sounds not very good to me. For this reason, we should disable the Hive Folder syncing.
Still on your local workstation, go to your SpiderOak preferences:
And disable the hive:
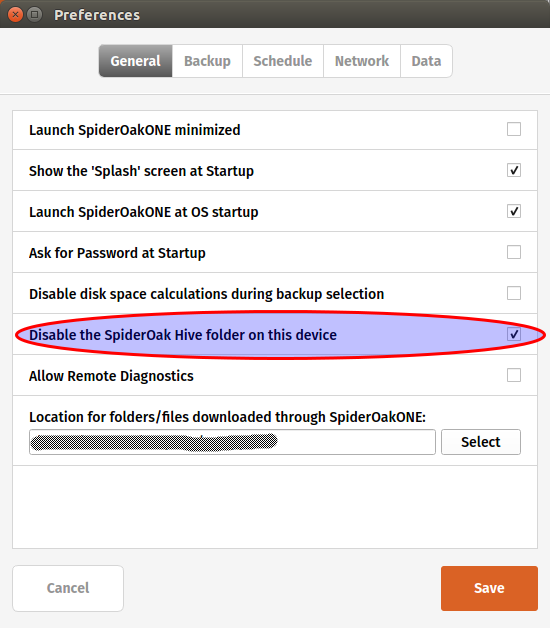
Note that if you don’t mind syncing your personal Hive on your DigitalOcean droplet, you can leave the option enabled.
Add your droplet as a SpiderOak device
Log to your DigitalOcean droplet by typing:
ssh root@your-domain-or-droplet-ip
Open your sources.list file
nano /etc/apt/sources.list
And add the following line at the end:
deb http://apt.spideroak.com/ubuntu-spideroak-hardy/ release restricted
Save, exit and run
apt-get update
If you get the following error:
W: GPG error: http://apt.spideroak.com release Release: The following signatures couldn't be verified because the public key is not available: NO_PUBKEY A6FF22FF08C15DD0
Look at it straight in the eye and IGNORE IT without showing mercy.
You’re now ready to install SpiderOak
apt-get install spideroakone
We must now configure SpiderOak but we don’t have any GUI on our server. What will we do? Simple, we just run the following command:
SpiderOakONE --setup=-
You will have to provide your SpiderOak login info.
Login: [email protected] Password: Logging in... Getting list of devices... id name 1 your_local_workstation To reinstall a device, enter the id (leave blank to set up a new device):
Don’t type any number. Simply press Enter as suggested to set up a new device. It will ask for the name of the device. Enter a descriptive name, something like myapp-droplet. Wait until the end of the syncing process. It may take several minutes, be patient!
Let’s create a folder for our DB backups
mkdir /home/dokku/db_backups
Then we include this folder in SpiderOak:
SpiderOakONE --include-dir=/home/dokku/db_backups
The output should look like this:
Including... New config: Current selection on device #2: u'myapp-droplet' (local) Dir:/home/dokku/db_backups Dir:/root/SpiderOak Hive ExcludeFile:/root/SpiderOak Hive/.Icon.png ExcludeFile:/root/SpiderOak Hive/Desktop.ini ExcludeFile:/root/SpiderOak Hive/Icon ExcludeFile:/root/SpiderOak Hive/.directory
Great, SpiderOak is all configured! Time to setup our database backups.
Create a shell script
Create a new file in /home/dokku and name it backup_db.sh. Paste the following:
#!/bin/bash /usr/local/bin/dokku postgres:export myapp > "/home/dokku/db_backups/myapp-`date +%Y-%m-%d`.dump" /usr/bin/SpiderOakONE --batchmode exit
Give the correct permission to the file:
chmod +x /home/dokku/backup_db.sh
As you can see, we use our Dokku postgres plugin to dump our db and we gzip the result in our db_backups folder. Then we run SpiderOakONE with the –batchmode flag to make it do its thing and shutdown immediately after.
Setup a cronjob
To automate our DB backups, we’ll add a cronjob.
crontab -e
Add the following line, save and exit:
0 5 * * * /home/dokku/backup_db.sh OUT_BACKUP 2>&1
It will run our backup script at 5am everyday. That’s all we need for now. Hmm… perhaps you don’t want to wait at 5am just to test if the script works. In this case, run the script directly.
cd /home/dokku ./backup_db.sh
The call to “SpiderOakONE –batchmode” will probably make this command run slowly. I don’t know what SpiderOak is doing exactly but sometimes it can take several minutes to complete the syncing.
Once it finally completes, go back to your local workstation to see if you can find your backup.
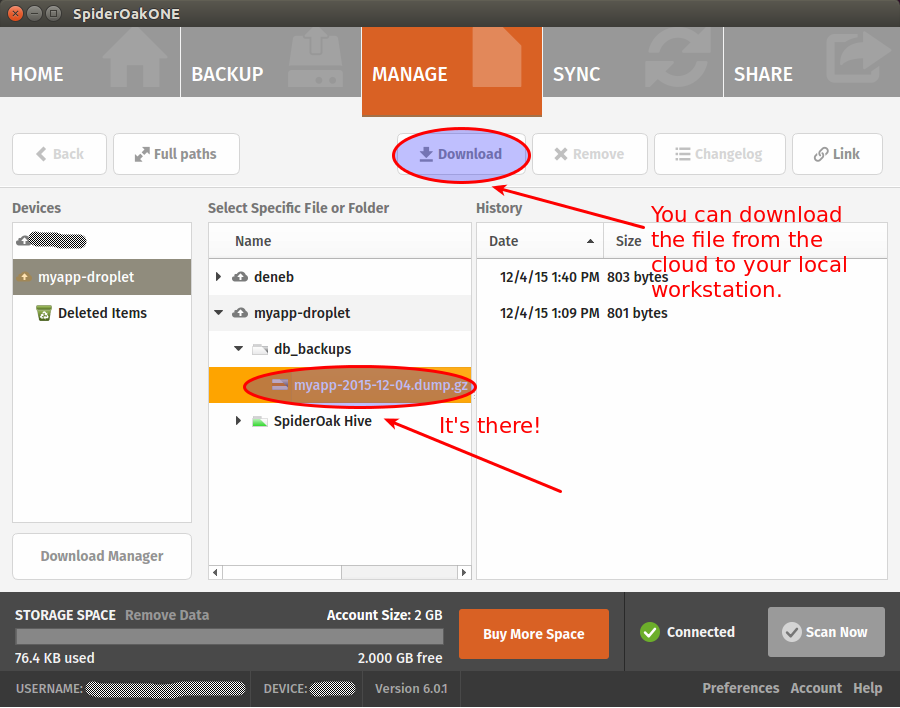
If you want, you can make sure that you are able to restore your backup before calling it a day (have a look at the dokku postgres:import command to that end). Restoring postgres databases usually gives of warnings but it’s generally safe to ignore them. Still, you’re better to make sure everything work as expected.
That’s it! You now have automated database backups on a zero-knowledge cloud architecture. Hope you enjoyed this tutorial! As usual, your comments are much appreciated.
You need to mention that SpiderOakONE is not FREE (however it has FREE 60-days Trial period).
You’re right, I’ve updated the post.
Thanks for the article.
As someone who already has Dropbox. Google Drive, OneDrive and iCloud, it seems unnecessary to pay for yet another cloud storage – is there an option to use one of the above instead?
Cheers, Dave
Dave, I don’t know if all these cloud providers you listed can be installed and configured easily on a server without a GUI, but if it’s not the case, you could try setting it up using X11 forwarding http://www.cyberciti.biz/tips/running-x-window-graphical-application-over-ssh-session.html
That’s said, I guess you would still need a way to have your cloud client run as a daemon on your server so it can sync automatically without your intervention.
There is also the ownCloud open source option that let you host your files yourself (or find a trusted and free provider). Maybe it would be a nice alternative to SpiderOak but I did not try it myself so I cannot say more.
Hi,
I think it is better to do not gzip your database dump as compressing your data doesn’t help the de-duplication process as SpiderOak client will have to calculate the new block each time
https://spideroak.com/faq/how-do-i-get-the-best-backup-deduplication-from-compressed-files
https://spideroak.com/manual/backup-explained
http://www.elsotanillo.net/2011/09/backing-up-a-cpanel-hosting-account/
Without the compression your first backup will take long time but the next ones will be quicker as SpiderOak client will sent only the differences between days.
So you will have 2 advantages:
* Less backup time.
* Less space occupped on your SpiderOak account.
Hope it helps!
Best regards
Interesting, Juan! I’ll certainly try it to see how it goes. Thanks
Thanks for the post Frank.
I wonder why not use something like ‘whenever’ and ‘backup’ gems and host the DB dumps on Amazon S3? have you tried this setup before?
That’s interesting, thanks for the suggestion Karim! Might be the subject for another post 🙂 I chose SpiderOak mainly because of their zero knowledge architecture. I’m impressed by their commitment on privacy.
Frank, Thanks for getting back. I appreciate it 🙂